Прочитал свое первое сообщение в этом блоге. Да, блог вести я перестал и пока не уверен возобновлю ли это. Но после 7 лет после того сообщения и того переезда, должен отметить, что решение поменять работу и город, принятое на семейном совете :), было абсолютно правильным. То, что мы получили, увидели и добились за эти 7 лет - все это результат того решения в том 2006 г. Все хорошо! Двигаемся дальше! :)
Saturday, August 24, 2013
Wednesday, April 24, 2013
10775 Course (Syllabus): Сообщения об ошибках Sys.Messages
В таблице Sys.Messages SQL-сервер хранит все известные сообщения об ошибках.
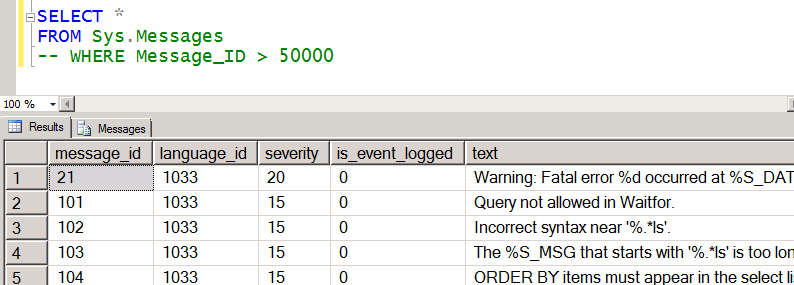
В таблице Sys.Messages заразервировано до 50тыс. строк, поэтому если мы собираемся использовать собственные ошибки, то нам необходимо их зарегистрировать под номерами боле 50000.
Добавить свое сообщение об ошибке можно при помощи процедуры sp_AddMessage
EXECUTE sp_AddMessage
@msgnum = 50001,
@severity =19,
@msgtext = 'My text or description of this message',
@with_log = 'TRUE' -- чтобы это сообщение можно было использовать в Alerts
Monday, April 22, 2013
10775 Course (Syllabus)
*.ldf and *.mdf files
There are *.mdf (main data file) and *.ldf (log data file) in MS SQL that used similar to Oracle datafiles and redo-logs. There is the checkpoint process in MS SQL that is responsible for
moving data from logfile to datafile. Is it similar to checkpoint of Oracle?
If you add second data file then its extension will be *.ndf. After adding any new data files SQL Server automatically spread data between all files.
For datafiles size management
- Use in properties of data file Enable Autogrowth in the Autogrowth /Maxsize
- Automatically: in Options - Auto Shrink - True (нежелательно ввиду работы этой опции на всю БД, особенно если мы располагаем файлы на разных дисковых массивах)
- Manually: Tasks - Shrink - Files (Вопрос: Как это сделать сценарием?)
Types of Shrink:
- Release unused space (быстрый, но не эффективный, т.к. сохраняется дефрагментация)
- Reorganize pages before releaseing unused space (включается дефрагментация)
- Empty file by migrating the data to other files in the same filegroup (вытеснение данных в другие файлы этой же FG (filegroup), что полезно, если нужно удалить файл)
Recovery model - модель восстановления
Full - all operations are kept in LOG file (reliable but keeps disk space)
Simple - operations saved in DATA file are automatically removed from the LOG file
Filegroups - something similar to Tablespaces in Oracle
1. Занимаемое место на диске
2. Точность восстановления
3. Скорость восстановления
4. Скорость резервирования
5. Простота стратегии
Вопросы, на которые стоит ответить прежде чем применить нужную стратегию восстановления
1. Где будут храниться резервные копии? Оперативные рядом с серверами, а долгие - подальше от офиса в DRS
2. Безопасность - нужно ли резервные копии защищать (шифровать, ограничивать физически и т.д.)
3. План восстановления - инструкция для дежурного инженера, она должна быть как можно более простой и понятной, чтобы любой инженер мог восстановить по ней данные.
4. Тестирование восстановления
Нужно определиться как делать тестовые восстановления.
Стратегии
- Full
-
http://msdn.microsoft.com/ru-ru/library/ms191239%28v=SQL.90%29.aspx
There are *.mdf (main data file) and *.ldf (log data file) in MS SQL that used similar to Oracle datafiles and redo-logs. There is the checkpoint process in MS SQL that is responsible for
moving data from logfile to datafile. Is it similar to checkpoint of Oracle?
If you add second data file then its extension will be *.ndf. After adding any new data files SQL Server automatically spread data between all files.
For datafiles size management
- Use in properties of data file Enable Autogrowth in the Autogrowth /Maxsize
- Automatically: in Options - Auto Shrink - True (нежелательно ввиду работы этой опции на всю БД, особенно если мы располагаем файлы на разных дисковых массивах)
- Manually: Tasks - Shrink - Files (Вопрос: Как это сделать сценарием?)
Types of Shrink:
- Release unused space (быстрый, но не эффективный, т.к. сохраняется дефрагментация)
- Reorganize pages before releaseing unused space (включается дефрагментация)
- Empty file by migrating the data to other files in the same filegroup (вытеснение данных в другие файлы этой же FG (filegroup), что полезно, если нужно удалить файл)
Recovery model - модель восстановления
Full - all operations are kept in LOG file (reliable but keeps disk space)
Simple - operations saved in DATA file are automatically removed from the LOG file
Filegroups - something similar to Tablespaces in Oracle
Backups
Что учесть при выборе стратегии восстановления?1. Занимаемое место на диске
2. Точность восстановления
3. Скорость восстановления
4. Скорость резервирования
5. Простота стратегии
Вопросы, на которые стоит ответить прежде чем применить нужную стратегию восстановления
1. Где будут храниться резервные копии? Оперативные рядом с серверами, а долгие - подальше от офиса в DRS
2. Безопасность - нужно ли резервные копии защищать (шифровать, ограничивать физически и т.д.)
3. План восстановления - инструкция для дежурного инженера, она должна быть как можно более простой и понятной, чтобы любой инженер мог восстановить по ней данные.
4. Тестирование восстановления
Нужно определиться как делать тестовые восстановления.
Стратегии
- Full
-
http://msdn.microsoft.com/ru-ru/library/ms191239%28v=SQL.90%29.aspx
Friday, April 19, 2013
Вопросы, которые помогут избежать 3-х ошибок при JOIN-ах
Вопросы, которые помогут избежать 3-х ошибок при JOIN-ах
1) Могут ли быть категории без товаров?
2) Не используется ли у меня COUNT(*) в сочетании с внешним JOIN-ом?
3) Опасно фильтровать результаты внешнего JOIN-а, а суммировать (или аггрегировать) по внутреннему.
1) Могут ли быть категории без товаров?
2) Не используется ли у меня COUNT(*) в сочетании с внешним JOIN-ом?
3) Опасно фильтровать результаты внешнего JOIN-а, а суммировать (или аггрегировать) по внутреннему.
Модули MS SQL: представления, процедуры, функции
-- Модули:
-- Представление VIEW
-- Процедура Procedure
-- Функция Function
-- также есть не модуль, но …
-- Табличное выражение WITH
--
Создать
представление
--Drop
view MyCatView
Create
view MyCatView
AS
SELECT
CategoryName, ProductName, UnitPrice
FROM
Categories C INNER JOIN Products P
ON
P.CategoryID=C.CategoryID
AND
CategoryName='seafood'
Group
BY CategoryName, ProductName, UnitPrice
GO
---
-- Обратиться к представлению
SELECT * from MyCatView
---
---Создать
процедуру
--DROP
PROCEDURE MyProc1
CREATE
PROCEDURE MyProc1
@CAT int, @PROD int
AS
SELECT
CategoryName, ProductName, UnitPrice
FROM
Categories C INNER JOIN Products P
ON
P.CategoryID=C.CategoryID
--
AND CategoryName='seafood'
AND
P.CategoryID > @CAT
AND
P.UnitPrice > @PROD
Group
BY CategoryName, ProductName, UnitPrice
GO
---
--Выполнить процедуру
EXECUTE MyProc1 5, 20
-- Создать функцию
--DROP
FUNCTION MyFunc1
CREATE
FUNCTION MyFunc1 (
@CAT int
, @PROD int
)
RETURNS TABLE
AS
RETURN
SELECT
CategoryName, ProductName, UnitPrice
FROM
Categories C INNER JOIN Products P
ON
P.CategoryID=C.CategoryID
--
AND CategoryName='seafood'
AND
P.CategoryID > @CAT
AND
P.UnitPrice > @PROD
Group
BY CategoryName, ProductName, UnitPrice
GO
---
--
Вызвать
функцию
SELECT
*
FROM
MyFunc1 (1,2)
WHERE UnitPrice>20
Одна задачка при помощи Subquery, JOIN и APPLY
-- Сколько в каждой категории
(CategoryName)
-- товаров в продаже
(Discontinued=0) и склолько снято с продаж (Discontinued=1)?
--
-- Подзапросами
SELECT CategoryName,
(
SELECT
Count(*)
From
Products
WHERE
Discontinued=0
AND
CategoryID = Categories.CategoryID
)
AS Cont
,
(
SELECT
Count(*)
From
Products
WHERE
Discontinued=1
AND
CategoryID = Categories.CategoryID
)
AS Disc
FROM Categories
--
|
-- Джойнами
SELECT CategoryName, Count(DISTINCT P1.ProductID) AS Con , Count(DISTINCT P2.ProductID) As Discont
FROM Categories C LEFT JOIN Products P1
ON C.CategoryID=P1.CategoryID
AND P1.Discontinued=0
LEFT JOIN Products P2
ON C.CategoryID=P2.CategoryID
AND P2.Discontinued=1
GROUP BY CategoryName
--
|
-- APPLY Джойнами
SELECT CategoryName, P1.Discon, P2.Cont
FROM Categories C CROSS APPLY (
SELECT Count(*) AS Discon
FROM Products
WHERE Discontinued=1
AND CategoryID=C.CategoryID
) P1
CROSS APPLY (
SELECT Count(*) AS Cont
FROM Products
WHERE Discontinued=0
AND CategoryID=C.CategoryID
) P2
Order by
C.CategoryName
|
Thursday, April 18, 2013
Когда юзать CROSS APPLY
Если в задаче требуется для каждого элемента списка одной таблицы найти список строк из другой таблицы, например, для каждого продавца показать три его любимых города или вывести для каждого продавца три его последних заказа за 1998 год.
SELECT FirstName+ ' ' + LastName, MyList.*
-- FROM Employees E CROSS APPLY
FROM Employees E OUTER APPLY -- Выберем OUTER APPLY, чтобы увидеть еще и нулевые записи NULL для тех, кто не отправлял вообще ничего в свой город
(
SELECT TOP (3) WITH TIES OrderID
FROM Orders
WHERE EmployeeID = E.EmployeeID
AND ShipCITY=E.City
ORDER BY OrderDate ASC
) MyList
Order by FirstName+ ' ' + LastName
При этом учитывайте, что CROSS APPLY аналогичен INNER JOIN, а OUTER APPLY - LEFT JOIN
вывести для каждого продавца три его последних заказа за 1998 год.
Подготовим подзапрос
для определения 3 последних заказов продавца 1
SELECT
TOP (3) *
FROM
Orders
WHERE
Year (OrderDate) = 1998
AND
EmployeeID = 1
ORDER
BY OrderDate DESC
Сделаем к этому
подзапросу CROSS APPLY
SELECT
*
FROM
Employees E CROSS APPLY (
SELECT TOP (3) *
FROM Orders
WHERE Year (OrderDate) = 1998
AND EmployeeID =E.EmployeeID
ORDER BY OrderDate DESC
) MyList
ORDER
BY E.EmployeeID
-- для каждого продавца показать три первых
номера заказа, которые он отправил в свой родной город
-- FROM Employees E CROSS APPLY
FROM Employees E OUTER APPLY -- Выберем OUTER APPLY, чтобы увидеть еще и нулевые записи NULL для тех, кто не отправлял вообще ничего в свой город
(
SELECT TOP (3) WITH TIES OrderID
FROM Orders
WHERE EmployeeID = E.EmployeeID
AND ShipCITY=E.City
ORDER BY OrderDate ASC
) MyList
Order by FirstName+ ' ' + LastName
Subscribe to:
Comments (Atom)
